Go历史
Go语言之父: Rob Pike
很多 Go 语言初学者经常称这门语言为 Golang,其实这是不对的:“Golang”仅应用于命名 Go 语言官方网站,而且当时没有用 go.com 纯粹是这个域名被占用了而已。
Go语言发展里程碑: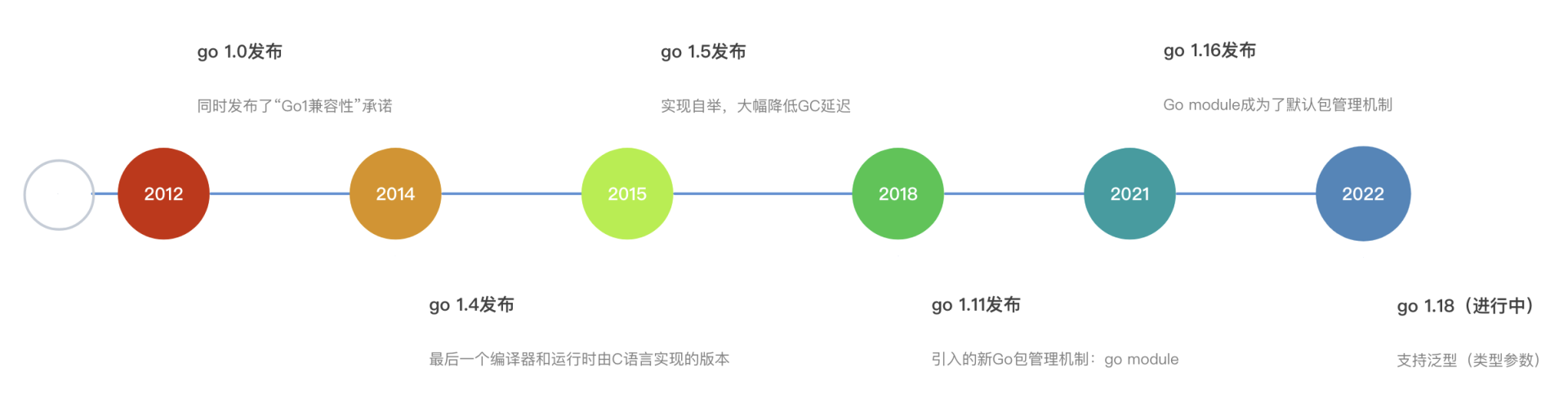
Go 1.4 引入 internal 包机制,增加了 internal 目录
设计哲学
- 简单
- 仅有 25 个关键字,主流编程语言最少
- 内置垃圾收集,降低开发人员内存管理的心智负担
- 首字母大小写决定可见性,无需通过额外关键字修饰
- 变量初始为类型零值,避免以随机值作为初值的问题
- 内置并发支持,简化并发程序设计
- 原生提供完善的工具链,开箱即用
- 显式
- 显式类型转换
- 显式的基于值比较的错误处理方案(返回error,开发者决定如何处理)
组合
- 类型嵌入(垂直组合,本质上是一种“能力继承”)
- 接口类型(水平组合,能力委托,降低耦合)
1
2
3
4// $GOROOT/src/io/ioutil/ioutil.go
func ReadAll(r io.Reader)([]byte, error)
函数 ReadAll 通过 io.Reader 这个接口,将 io.Reader 的实现与 ReadAll 所在的包低耦合地水平组合在一起了,从而达到从任意实现 io.Reader 的数据源读取所有数据的目的。
并发
- 面向多核、原生支持并发
- go关键字轻松创建协程
- goroutine 调度的切换不用陷入(trap)操作系统内核层完成,代价很低。因此,一个 Go 程序中可以创建成千上万个并发的 goroutine
- 面向工程
- 重新设计编译单元和目标文件格式, 实现 Go 源码快速构建
- 如果源文件导入它不使用的包,则程序将无法编译,可以保证在构建程序时不会编译额外的代码,从而最大限度地缩短编译时间
- 去除包的循环依赖,循环依赖会在大规模的代码中引发问题
- 增加类型别名(type alias),支持大规模代码库的重构
如果说一门编程语言是“自带电池”,则说明这门语言标准库功能丰富,多数功能不需要依赖外部的第三方包或库,Go 语言恰恰就是这类编程语言。
典型目录结构
可执行程序项目
1 |
|
库项目
1 | $tree -F lib-layout |
构建演进
Go 程序的构建过程就是确定包版本、编译包以及将编译后得到的目标文件链接在一起的过程
Go 语言的构建模式历经了三个迭代和演化过程:
- GOPATH
- 1.5 版本的 Vendor 机制
- Go Module
使用最小版本选择进行包依赖版本选择
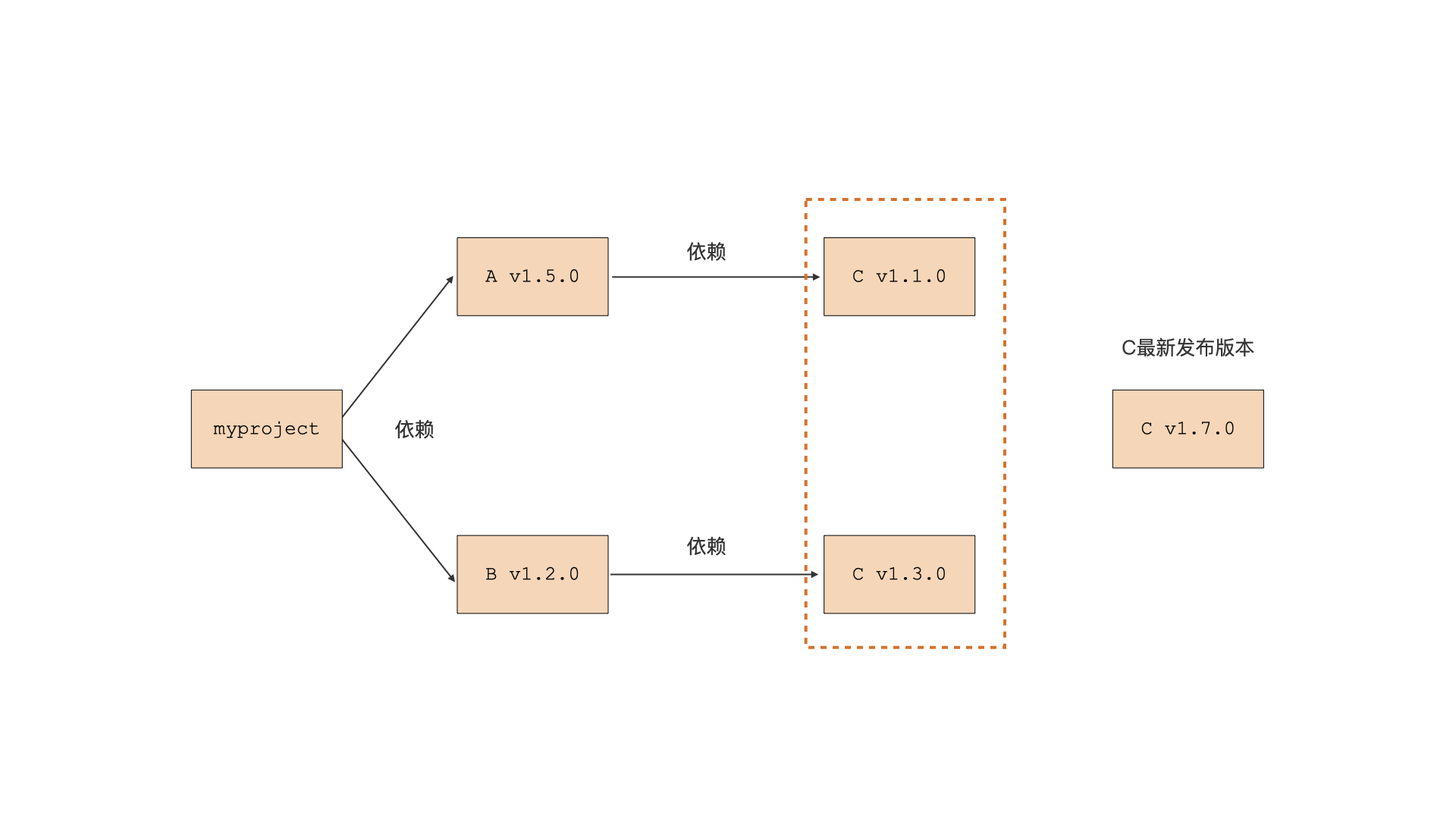
A 明明说只要求 C v1.1.0,B 明明说只要求 C v1.3.0。所以 Go 会在该项目依赖项的所有版本中,选出符合项目整体要求的“最小版本”。这个例子中,C v1.3.0 是符合项目整体要求的版本集合中的版本最小的那个,于是 Go 命令选择了 C v1.3.0,而不是最新最大的 C v1.7.0。并且,Go 团队认为“最小版本选择”为 Go 程序实现持久的和可重现的构建提供了最佳的方案。
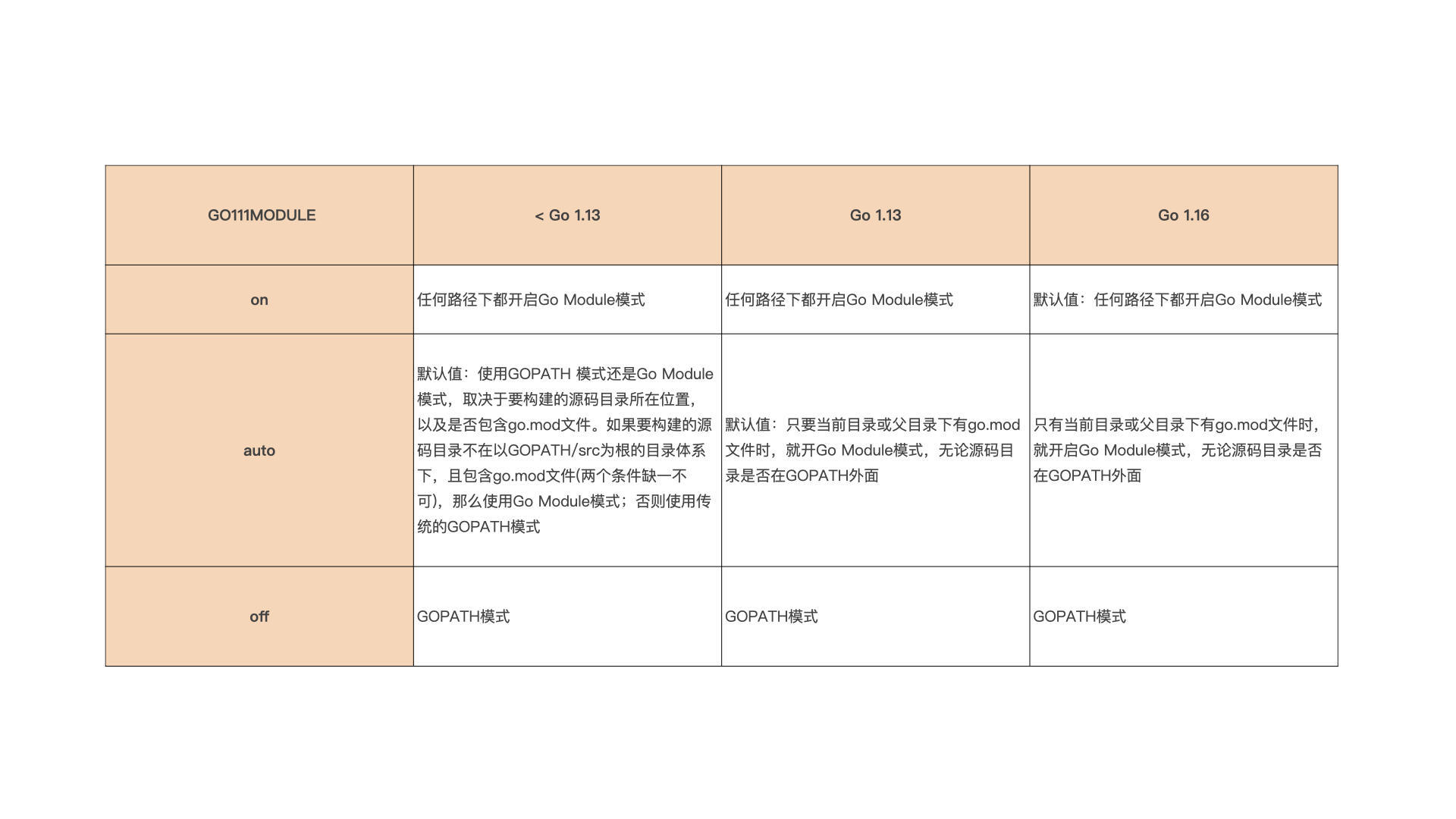
GO111MODULE变量
包依赖常用命令
列出所有依赖:
1
go list -m all
查询依赖包版本:
1
2$go list -m -versions github.com/sirupsen/logrus
github.com/sirupsen/logrus v0.1.0 v0.1.1 v0.2.0 v0.3.0 v0.4.0 v0.4.1 v0.5.0 v0.5.1 v0.6.0 v0.6.1 v0.6.2 v0.6.3 v0.6.4 v0.6.5 v0.6.6 v0.7.0 v0.7.1 v0.7.2 v0.7.3 v0.8.0 v0.8.1 v0.8.2 v0.8.3 v0.8.4 v0.8.5 v0.8.6 v0.8.7 v0.9.0 v0.10.0 v0.11.0 v0.11.1 v0.11.2 v0.11.3 v0.11.4 v0.11.5 v1.0.0 v1.0.1 v1.0.3 v1.0.4 v1.0.5 v1.0.6 v1.1.0 v1.1.1 v1.2.0 v1.3.0 v1.4.0 v1.4.1 v1.4.2 v1.5.0 v1.6.0 v1.7.0 v1.7.1 v1.8.0 v1.8.1降级依赖包版本:
1
2go get github.com/sirupsen/logrus@v1.7.0
go mod edit -require=github.com/sirupsen/logrus@v1.7.0go mod vendor
go mod vendor 命令在 vendor 目录下,创建了一份这个项目的依赖包的副本,并且通过 vendor/modules.txt 记录了 vendor 下的 module 以及版本
如果我们要基于 vendor 构建,而不是基于本地缓存的 Go Module 构建,我们需要在 go build 后面加上 -mod=vendor 参数。
在 Go 1.14 及以后版本中,如果 Go 项目的顶层目录下存在 vendor 目录,那么 go build 默认也会优先基于 vendor 构建,除非你给 go build 传入 -mod=mod 的参数。
监听操作系统信号
1 | osChan := make(chan os.Signal, 1) |
初始化顺序
Go 在包中按照“常量 -> 变量 -> init 函数”的顺序先对 pkg3 包进行初始化
变量
包级变量只能使用带有 var 关键字的变量声明形式,不能使用短变量声明形式
变量声明选择
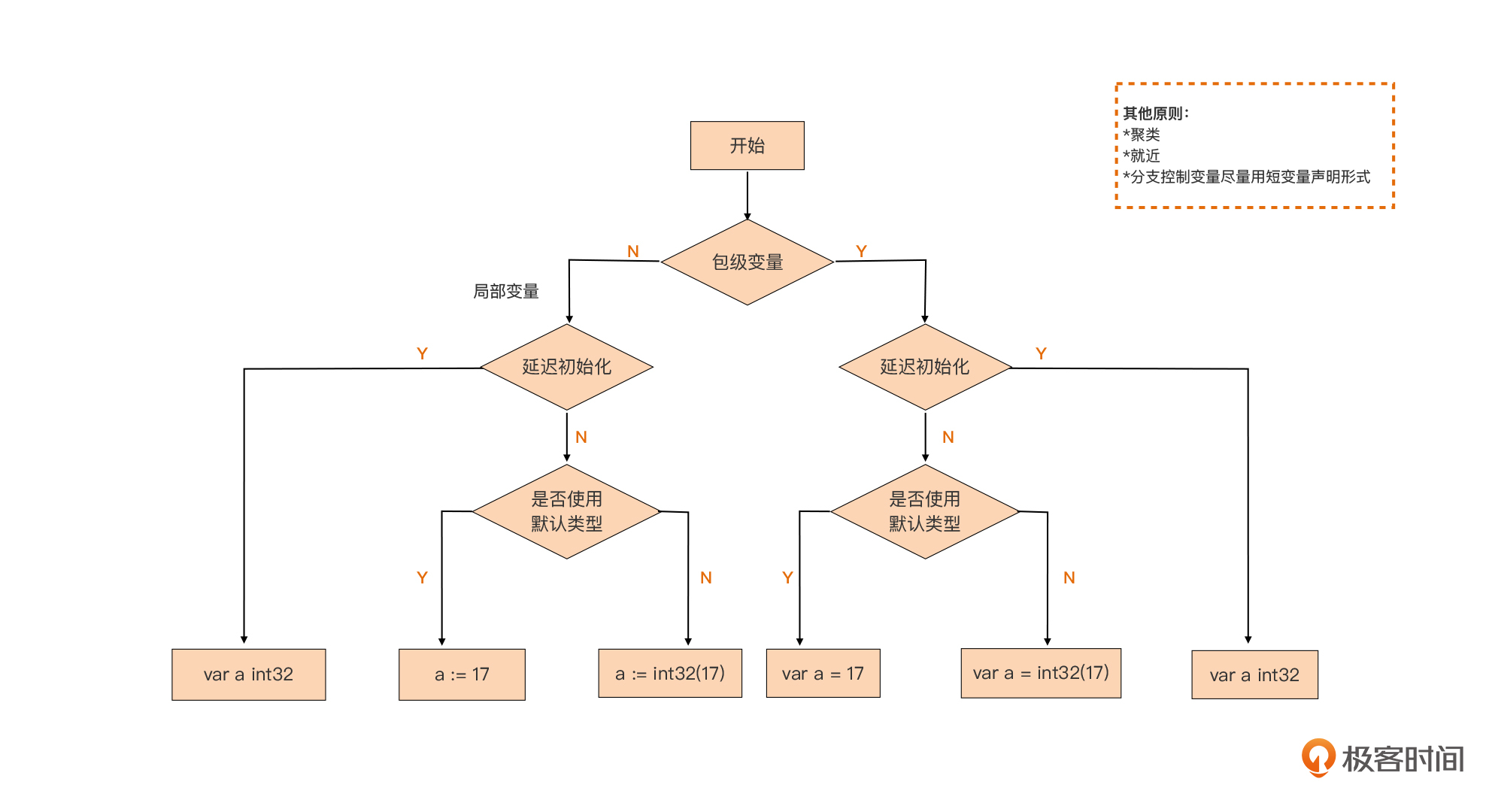
利用工具检测变量遮蔽问题
1 | go install golang.org/x/tools/go/analysis/passes/shadow/cmd/shadow@latest |
常量
Go 语言在常量方面的创新包括下面这几点:
- 支持无类型常量
- 支持隐式自动转型
- 可用于实现枚举。
隐式转型说的就是,对于无类型常量参与的表达式求值,Go 编译器会根据上下文中的类型信息,把无类型常量自动转换为相应的类型后,再参与求值计算,这一转型动作是隐式进行的
位于同一行的 iota 即便出现多次,多个 iota 的值也是一样
如果我们要略过 iota = 0,从 iota = 1 开始正式定义枚举常量,我们可以效仿下面标准库中的代码:1
2
3
4
5
6
7
8
// $GOROOT/src/syscall/net_js.go
const (
_ = iota
IPV6_V6ONLY // 1
SOMAXCONN // 2
SO_ERROR // 3
)
类型
字符串
内部表示
1 |
|
迭代形式
Go 有两种迭代形式:常规 for 迭代与 for range 迭代
通过这两种形式的迭代对字符串进行操作得到的结果是不同的。
- 经过常规 for 迭代后,我们获取到的是字符串里字符的 UTF-8 编码中的一个字节
- 通过 for range 迭代,我们每轮迭代得到的是字符串中 Unicode 字符的码点值,以及该字符在字符串中的偏移值
比较类型
函数类型、map 类型自身,以及切片类型是不能作为 map 的 key 类型的。
map
map 可以自动扩容,map 中数据元素的 value 位置可能在这一过程中发生变化,所以 Go 不允许获取 map 中 value 的地址,这个约束是在编译期间就生效的。
递归定义
Go 语言不支持在结构体类型定义中,递归地放入其自身类型字段的定义方式, 但可以拥有自身类型的指针类型、以自身类型为元素类型的切片类型,以及以自身类型作为 value 类型的 map 类型的字段
原因:
一个类型,它所占用的大小是固定的,因此一个结构体定义好的时候,其大小是固定的。
但是,如果结构体里面套结构体,那么在计算该结构体占用大小的时候,就会成死循环。但如果是指针、切片、map等类型,其本质都是一个int大小(指针,4字节或者8字节,与操作系统有关),因此该结构体的大小是固定的,记得老师前几节课讲类型的时候说过,类型就能决定内存占用的大小。因此,结构体是可以接口自身类型的指针类型、以自身类型为元素类型的切片类型,以及以自身类型作为 value 类型的 map 类型的字段,而自己本身不行。
内存对齐:出于对处理器存取数据效率的考虑
对于各种基本数据类型来说,它的变量的内存地址值必须是其类型本身大小的整数倍
对于结构体而言,它的变量的内存地址,只要是它最长字段长度与系统对齐系数两者之间较小的那个的整数倍就可以了。但对于结构体类型来说,我们还要让它每个字段的内存地址都严格满足内存对齐要求。
在日常定义结构体时,一定要注意结构体中字段顺序,尽量合理排序,降低结构体对内存空间的占
1 |
|
label
带 label 的 continue 语句,通常出现于嵌套循环语句中,被用于跳转到外层循环并继续执行外层循环语句的下一个迭代,比如下面这段代码:
1 |
|
receiver
receiver 参数的基类型本身不能为指针类型或接口类型
1 |
|
1 | one |
1 |
|
Go 语言规定,T 类型的方法集合包含所有以 T 为 receiver 参数类型的方法,以及所有以 T 为 receiver 参数类型的方法。
T vs *T
选择 receiver 参数类型的三个原则:
- 如果 Go 方法要把对 receiver 参数代表的类型实例的修改,反映到原类型实例上,那么我们应该选择T 作为 receiver 参数的类型。
- 如果 receiver 参数类型的 size 较大,以值拷贝形式传入就会导致较大的性能开销,这时我们选择 *T 作为 receiver 类型可能更好些。
- 如果 T 类型需要实现某个接口,那我们就要使用 T 作为 receiver 参数的类型,来满足接口类型方法集合中的所有方法。
1 |
|
T 和 *T 类型的方法集合是有差别的:
- 类型 T 的方法集合 = T1 的方法集合 + *T2 的方法集合类型
- T 的方法集合 = T1 的方法集合 + *T2 的方法集合
- 结构体类型的方法集合包含嵌入的接口类型的方法集合;
- 当结构体类型 T 包含嵌入字段 E 时,T 的方法集合不仅包含类型 E 的方法集合,还要包含类型 E 的方法集合。
Go1.17新特性
支持将切片转换为数组指针,转换后的数组==长度==不能大于原切片的长度
1
2
3
4b := []int{11, 12, 13}
p := (*[3]int)(b) // 将切片转换为数组类型指针
p[1] = p[1] + 10
fmt.Printf("%v\n", b) // [11 22 13]Go Module 构建模式的变化:修剪的 module 依赖图(pruned module graph)
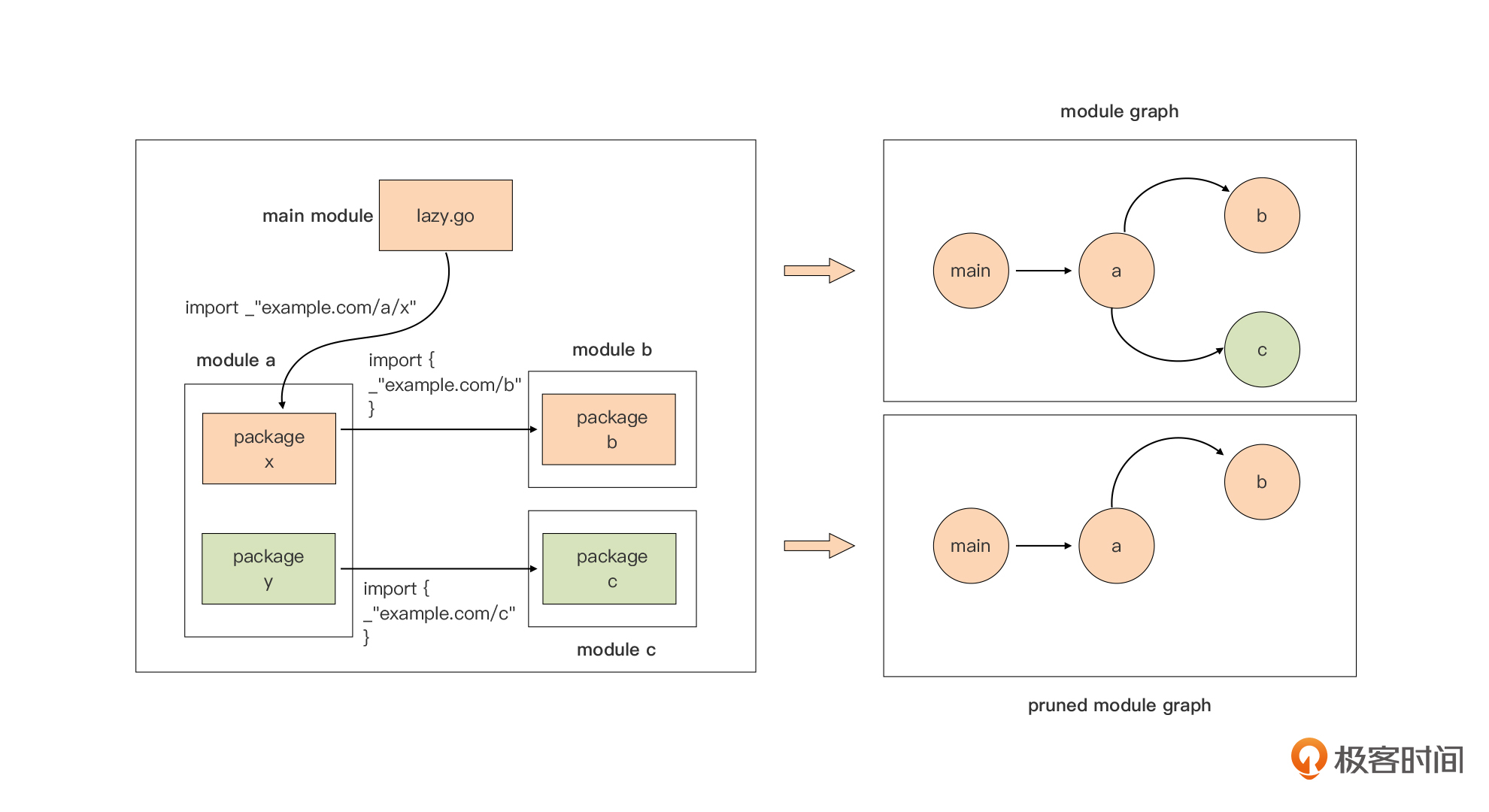
go get 已经不再被用来安装某个命令的可执行文件了 -> go install xxx@version- Go 编译器的变化
- 基于寄存器的调用惯例:在 AMD64 架构下率先实现了从基于堆栈的调用惯例到基于寄存器的调用惯例的切换。
- //go:build 形式的构建约束指示符

1
2
3
4//go:build linux && (386 || amd64 || arm || arm64 || mips64 || mips64le || ppc64 || ppc64le)
//go:build linux && (mips64 || mips64le)
//go:build linux && (ppc64 || ppc64le)
//go:build linux && !386 && !arm
并发模型
传统语言的并发模型是基于对内存的共享的, 一个符合 CSP 模型的并发程序应该是一组通过输入输出原语连接起来的 P 的集合
Goroutine 调度器的任务也就明确了:将 Goroutine 按照一定算法放到不同的操作系统线程中去执行。
如果 G 被阻塞在某个 channel 操作或网络 I/O 操作上时,M 可以不被阻塞,这避免了大量创建 M 导致的开销。但如果 G 因慢系统调用而阻塞,那么 M 也会一起阻塞,但在阻塞前会与 P 解绑,P 会尝试与其他 M 绑定继续运行其他 G。但若没有现成的 M,Go 运行时会建立新的 M,这也是系统调用可能导致系统线程数量增加的原因
无缓冲 channel 的惯用法:
- 用作信号传递(1 对 1 通知信号和 1 对 n 通知)
- 用于替代锁机制
带缓冲 channel 的惯用法:
- 用作消息队列
- 用作计数信号量(counting semaphore)
sync包
sync 包提供了 Go 语言的一系列低级同步原语。Channel 机制也是建立在低级同步原语的基础之上的,因此也叫做高级同步原语。在一些追求高性能的场景下,直接使用低级同步原语可以获得更好的性能。
- 读写锁适合应用在具有一定并发量且读多写少的场合
- atomic 包更适合一些对性能十分敏感、并发量较大且读多写少的场合