![]()
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎。
起源
Lucene是Doug Cutting(Hadoop之父)于1999年创建的基于Java语言开发的搜索引擎类库,并于2005年成为Apache顶级开源项目,具有高性能、易扩展的特点。但Lucene也存在以下局限:
- 只能基于Java语言开发
- 类库的接口学习曲线陡峭
- 原生并不支持水平扩展
于是Shay Banon在2004年基于Lucene开发了Compass,并在2010年重写了Compass,取名Elasticsearch,解决的主要问题:
- 支持分布式,可水平扩展
- 降低全文搜索的学习曲线,可以被任何编程语言调用
Elastic(ELK) Stack
简介
ELK Stack是Elastic公司推出的基于Elasticsearch、Kibana、Beats 和 Logstash等产品的企业解决方案,能够安全可靠地从任何来源获取任何格式的数据,然后对数据进行搜索、分析和可视化。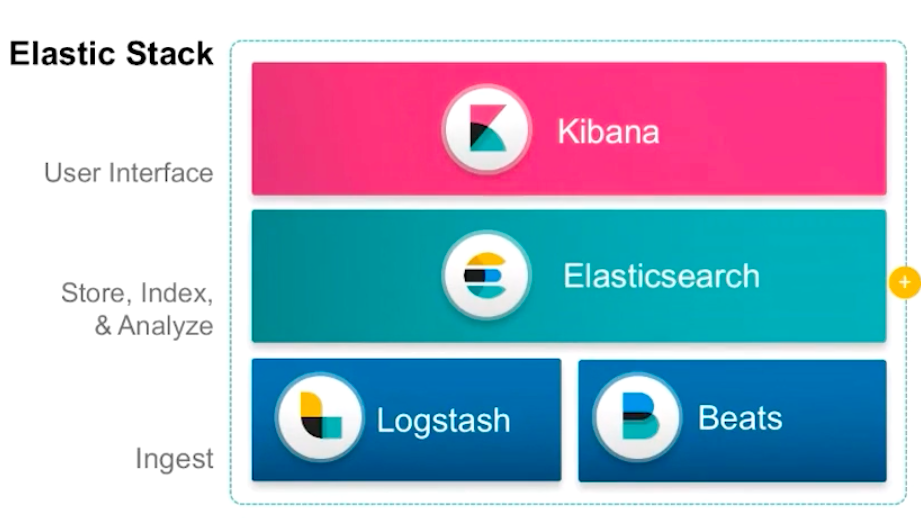
“ELK”是三个开源项目的首字母缩写,这三个项目分别是:Elasticsearch、Logstash 和 Kibana。
- Elasticsearch 是在 Apache Lucene 上构建的
分布式搜索和分析引擎。对各种语言、高性能和无架构 JSON 文档的支持使 Elasticsearch 成为各种日志分析和搜索使用案例的理想选择。 - Logstash 是服务器端
数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 Elasticsearch 等“存储库”中 - Kibana 是一种
数据可视化和挖掘工具,用于审查日志和事件。Kibana 提供易于使用的交互式图表、预构建的聚合和筛选器以及地理空间支持,使其成为可视化 Elasticsearch 中存储的数据的首选。
Elastic Stack 是 ELK Stack 的更新换代产品。
生态圈
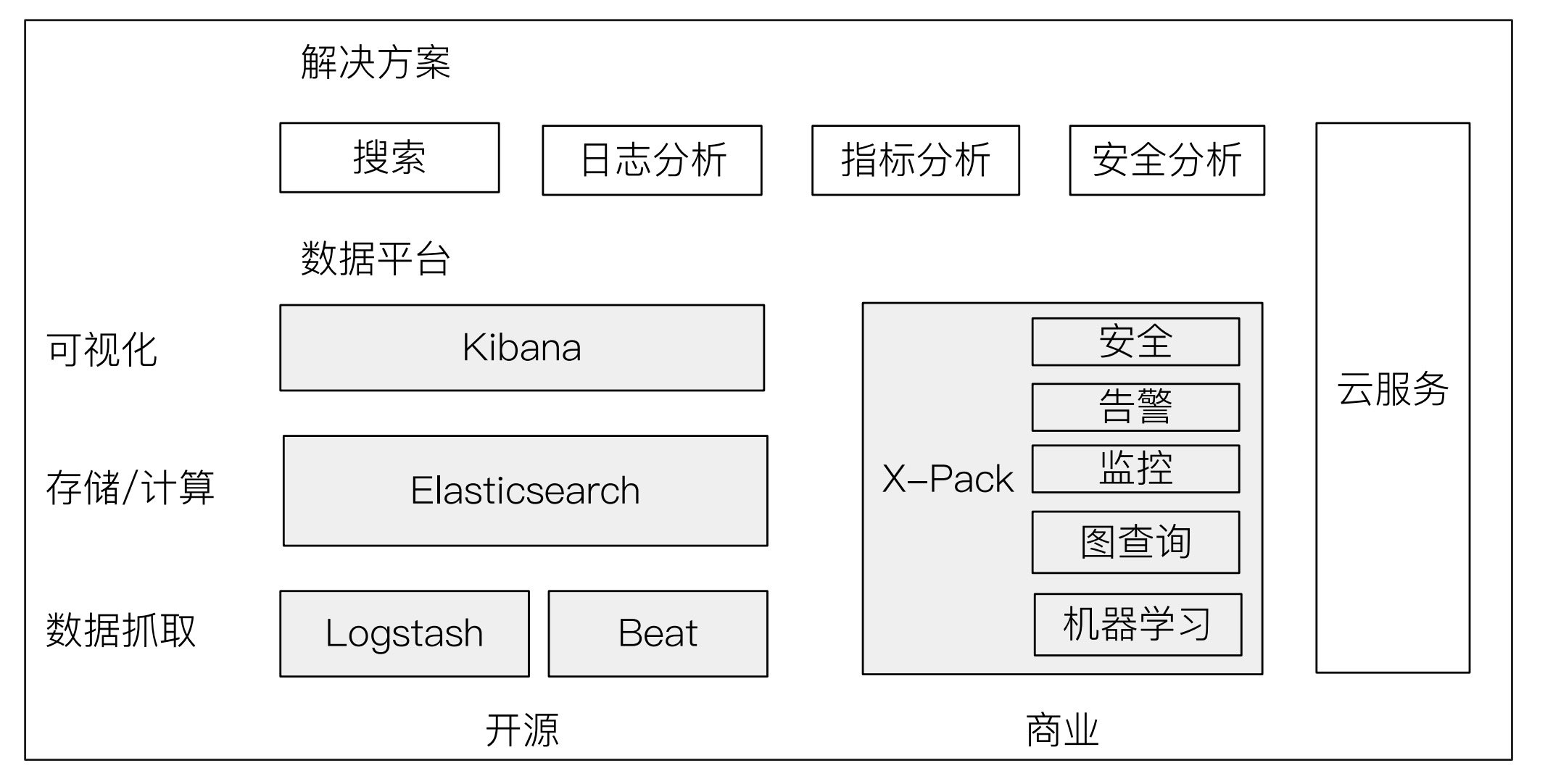
- Beats:轻量型
数据采集器。是一个免费且开放的平台,集合了多种单一用途数据采集器。它们从成百上千或成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。
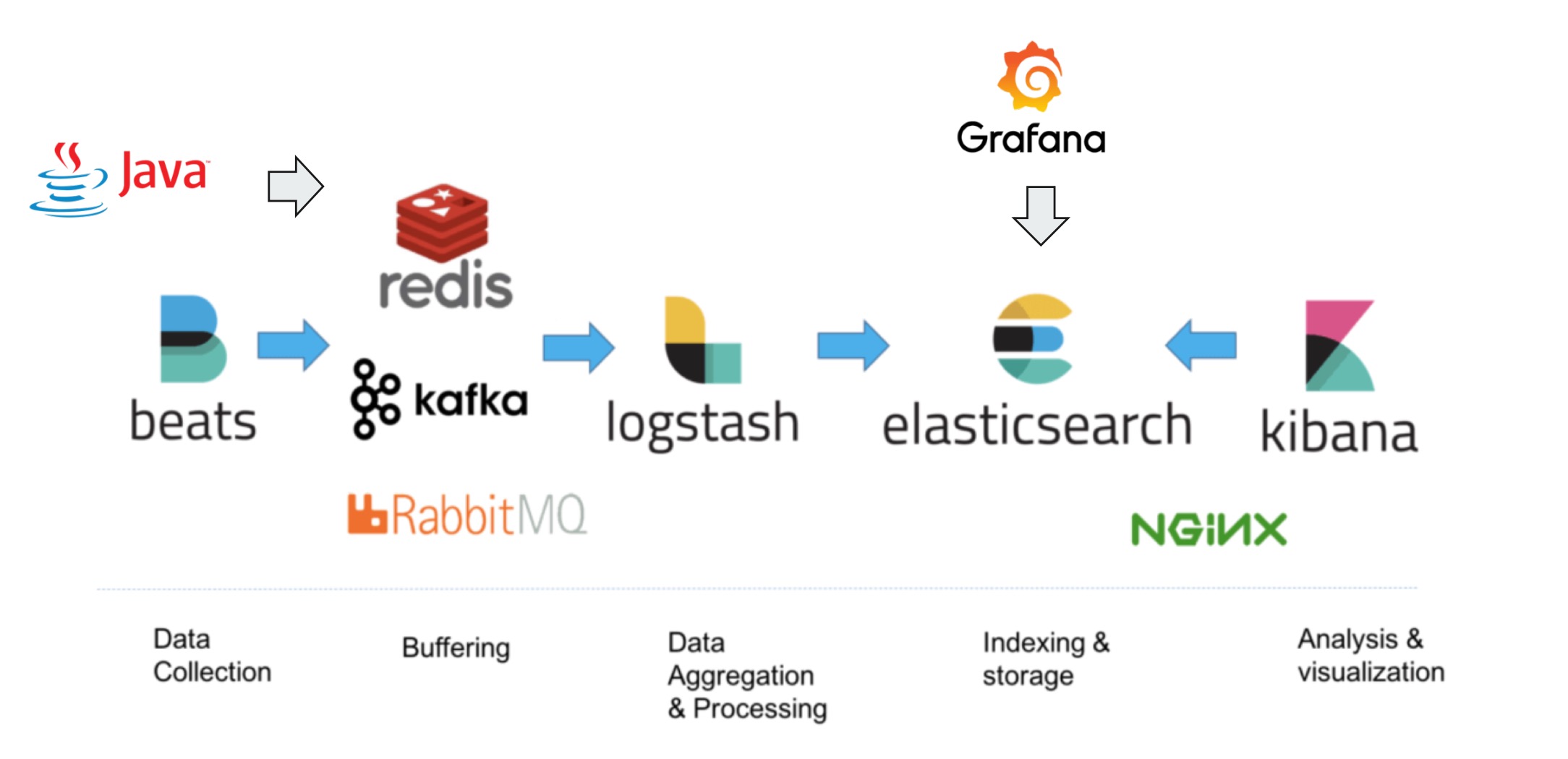
Beats与Logstash关系?
beats和logstash都可以从多个数据源采集数据并存储到ES。但Beats是用Golang语言开发的,更加轻量,支持的数据源也更多,而logstash更专注于数据转换,格式化等处理工作。所以工程上通常用beats来采集数据,然后发给logstash进行处理(数据生产较快时可通过kafka等MQ做数据缓冲再到logstash),logstash对数据进行转换处理后存储到ES。
- X-Pack: 商业化套件,部分功能支持免费使用。X-Pack 为 Elastic Stack 带来了一系列深度集成的企业级功能,其中包括安全、告警、监测、报告、图表分析、专用 APM UI 和 Machine Learning。
应用场景
- 网站搜索/垂直搜索/代码搜索
- 日志管理与分析/安全指标监控/应用性能监控/WEB抓取舆情分析
ES插件安装与查看
安装插件
以ik分词器为例,到release页面获取与安装的ES版本对应的ik分词器版本(支持在线安装和离线安装):1
bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.1.0/elasticsearch-analysis-ik-7.1.0.zip
查看插件
列出已安装插件:1
bin/elasticsearch-plugin list
或通过接口查看:1
2
3$ curl 'http://127.0.0.1:9200/_cat/plugins/'
VM-74-12-centos analysis-icu 7.1.0
VM-74-12-centos analysis-ik 7.1.0
常用插件
- ik分词器:一个第三方开发者开发的中文分词插件,支持自定义词典,支持两种Analyzer:
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query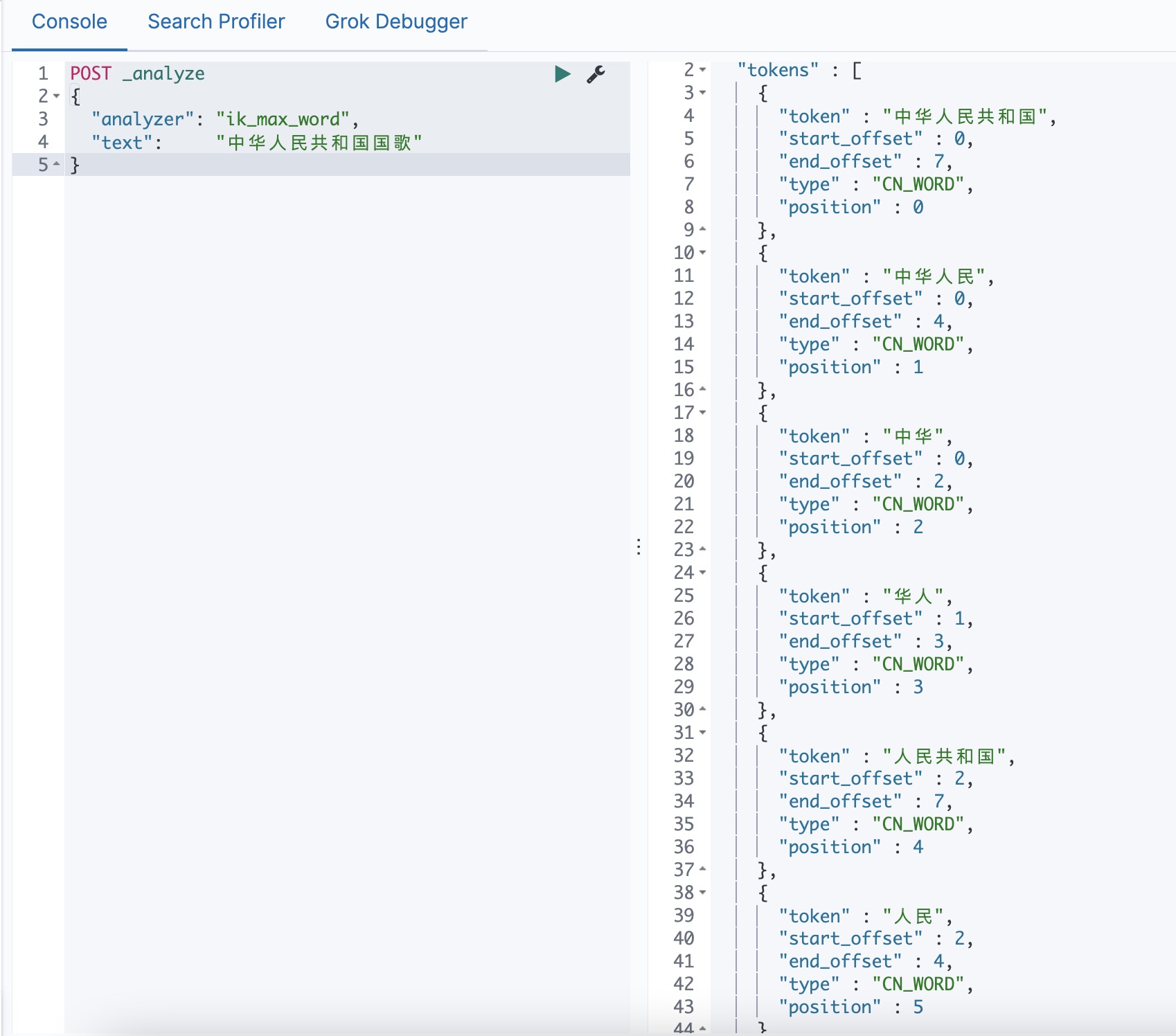
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询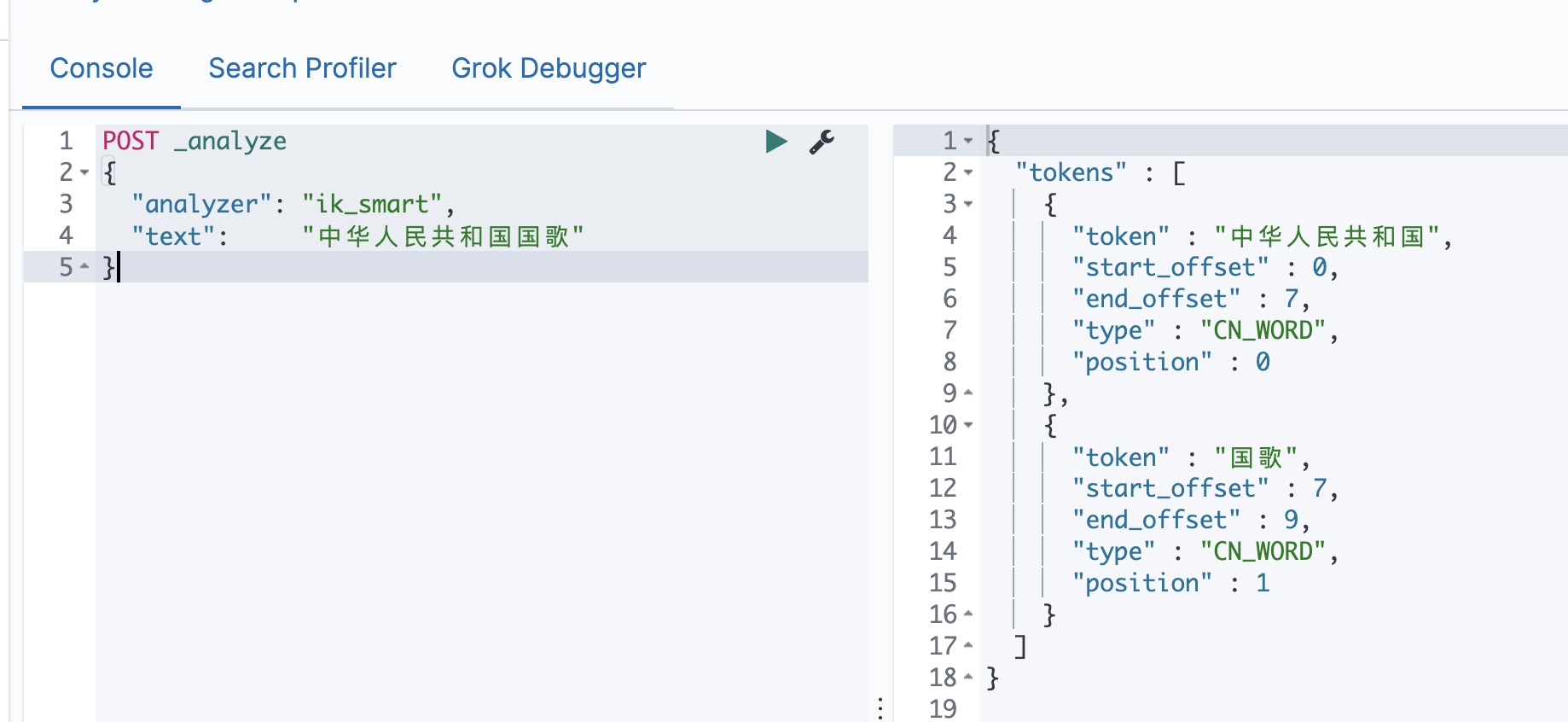
- 拼音分词器:用于汉字和拼音之间的转换,集成了NLP工具
基本概念
逻辑概念
与关系型数据库的类比(不那么恰当):
| RDBMS | ES |
|---|---|
| Table | Index/Type |
| Row | Document |
| Column | Field |
| Schema | Mapping |
| SQL | DSL |
- 文档(Document): ES是面向文档的,文档是所有可搜索数据的最小单位,例如日志文件的日志项,一部电影的信息等,文档会被序列化为JSON格式,保存在ES中
- 类型(Type): 由多个文档组成
在ES 7.0之前,一个index可以设置多个Types。6.0开始,Type已经被
Deprecated. 7.0开始,一个索引只能创建一个Type-_doc
为什么要移除多type?
单index,多type结构弊端:
- 在ES中同一Index 下,
同名 Field 类型必须兼容,即使是不同的Type - 同一Index下,TypeA的 Field 会占用 TypeB 的资源(互相消耗资源),会形成一种稀疏存储的情况。尤其是 doc value ,为什么这么说呢?doc value为了性能考虑会保留一部分的
磁盘空间,这意味着 TypeB 可能不需要这个字段的 doc_value 而 TypeA 需要,那么 TypeB 就被白白占用了一部分没有半点用处的资源; - Score
评分机制是 index-wide 的,不同的type之间评分也会造成干扰。
- 索引(Index): 文档的容器,是一类文档的结合,索引的不同语义
物理概念
- 集群:ES是天生支持分布式及水平扩展的,一个ES集群由1到多个节点共同组成。
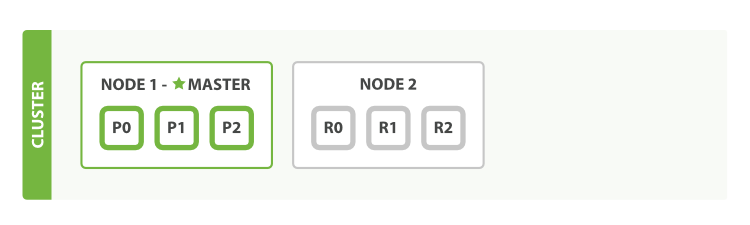
- 节点: 节点是一个Elasticsearch的实例,本质上是一个Java进程,一个节点上可能包含多个分片
主要有4种节点类型:
- 主节点(Master Node): 负责集群操作相关的内容,如创建或删除索引,跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点。
- 数据节点(Data Node): 存储索引数据的节点,主要对文档进行增删改查操作,聚合操作等。
- 协调节点(Coordinating Node): 处理路由请求,处理搜索,分发索引等操作,每个节点默认都起到了Coordinating Node的职责
- 预处理节点(Ingest Node):在索引数据之前可以先对数据做预处理操作
- 分片: ES索引实际上是指向一个或者多个物理分片的逻辑命名空间。通过分片可以实现
水平扩展和数据可用(故障转移)。一个分片是一个底层的工作单元,它仅保存了全部数据中的一部分。一个分片可以是主分片或者副本分片。 索引内任意一个文档都归属于一个主分片,所以主分片的数目决定着索引能够保存的最大数据量。一个副本分片只是一个主分片的拷贝。副本分片作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务。
在索引建立的时候就已经确定了主分片数,但是副本分片数可以随时修改。
1 | PUT /blogs |
集群健康状态
1 | GET /_cluster/health |
status 字段是我们最关心的,指示着当前集群在总体上是否工作正常。它的三种颜色含义如下:
- green: 所有的主分片和副本分片都正常运行。
- yellow: 所有的主分片都正常运行,但不是所有的副本分片都正常运行。
- red: 有主分片没能正常运行。
在开发机上运行多个ES实例
1 | bin/elasticsearch -E node.name=node1 -E cluster.name=longerwu-es -E path.data=node1_data -d |
查看集群节点:1
2
3
4GET /_cat/nodes
127.0.0.1 22 97 1 0.71 0.38 0.15 mdi * node1
127.0.0.1 28 97 1 0.71 0.38 0.15 mdi - node2
Cerebro
Cerebro:一个开源的elasticsearch web管理工具,提供了可视化界面以方便查看ES集群情况
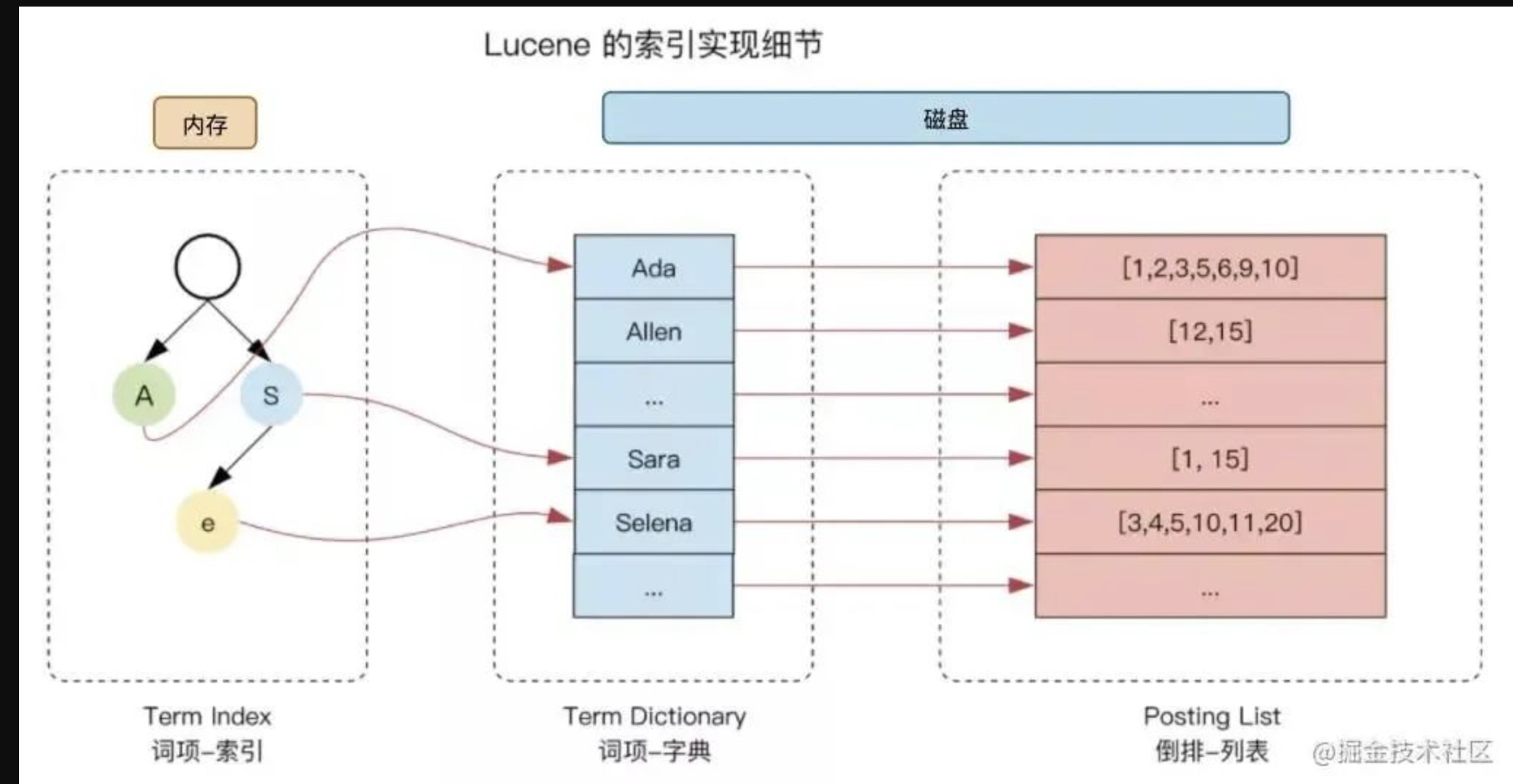
倒排索引(Inverted index)
正排索引vs倒排索引
- 正排索引: 文档id到文档内容和单词的关联
- 倒排索引: 单词到文档id的关系
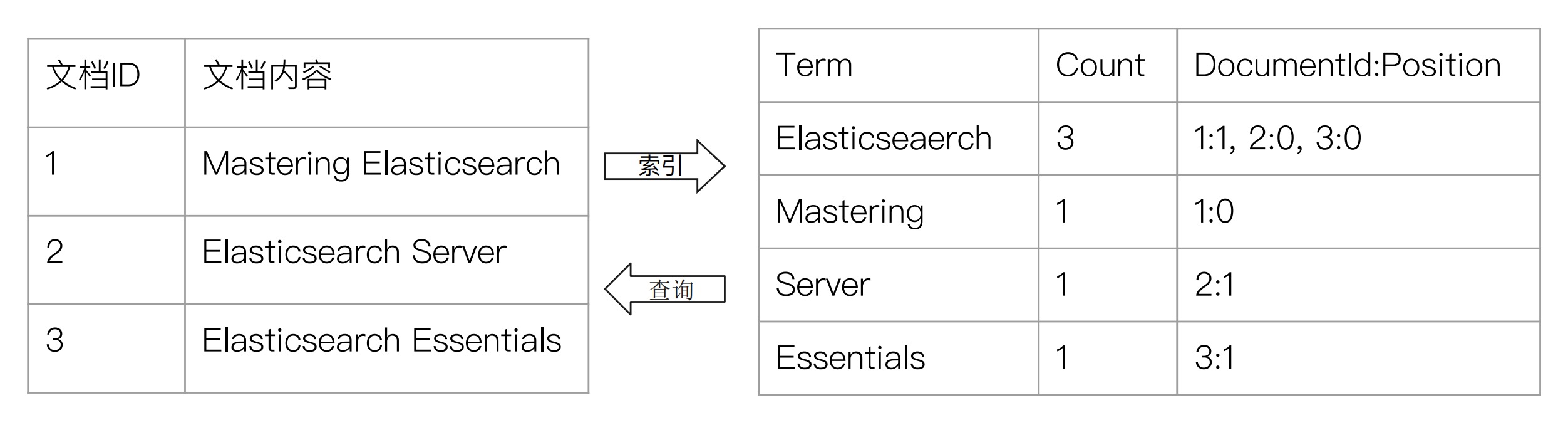
倒排索引的核心组成
单词词典(Term Dictionary):记录所有文档的单词,记录单词到倒排列表的关联关系
单词词典一般比较大,可以通过 B+ 树 或 哈希拉链法实现,以满足高性能的插入与查询
倒排列表(Posting List):记录了单词对应的文档结合,由倒排索引项(Posting)组成:
- 文档 ID
- 词频 TF(Term Frequency):该单词在文档中出现的次数,用于相关性评分
- 位置(Position):单词在文档中分词的位置。用于语句搜索(Phrase Query)
- 偏移(Offset):记录单词的开始结束位置,实现高亮显示
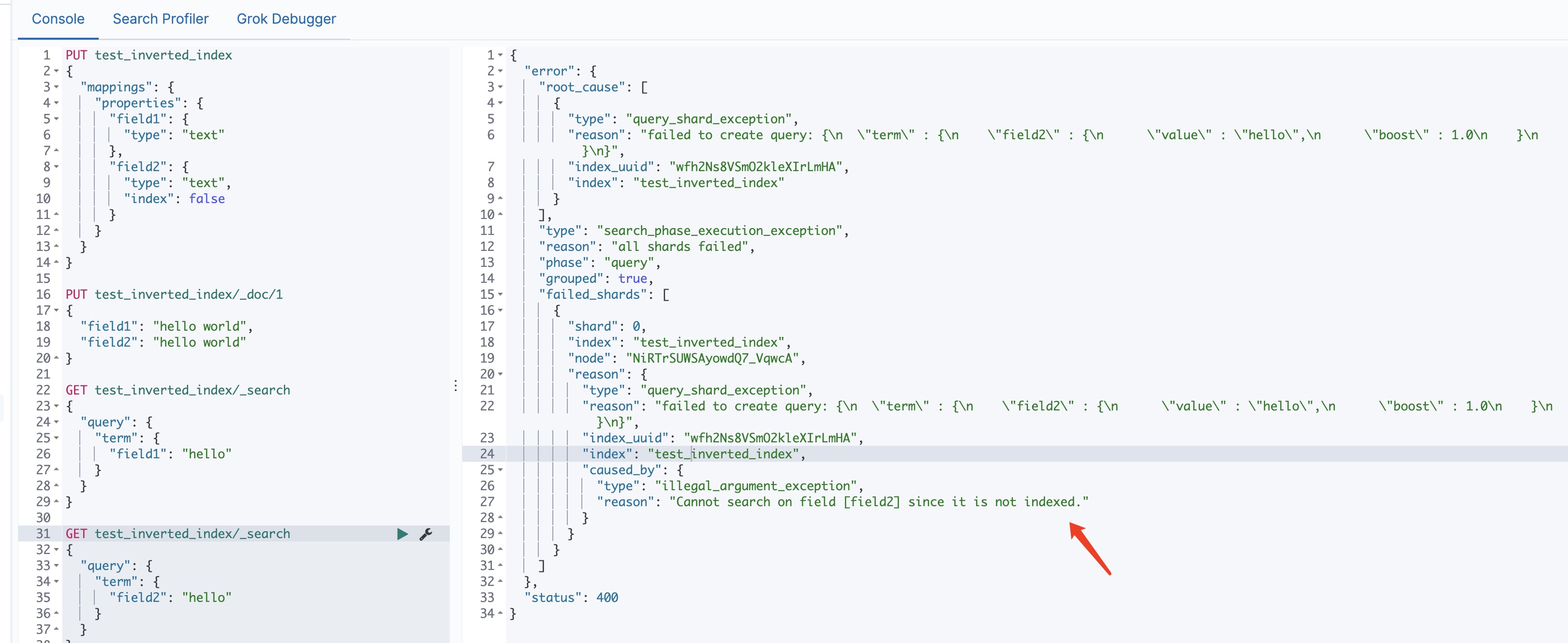
ES 的 JSON 文档中的每个字段,默认都有自己的倒排索引,可以针对某些字段不做索引(在mapping中设置index为false)
- 优点:节省存储空间
- 缺点:字段无法被搜索
1 | PUT test_inverted_index |
分词
Analysis和Analyzer
- Analysis, 也叫分词,是将文本转换为一系列单词的过程。
- Analyzer, 分词器,Analysis是通过Analyzer实现的
Analyzer组成
- Charater Filter: 针对原始文本处理,例如去掉html
- Tokenizer: 按照规则切分为单词
- Toker Filter: 对切分的单词进行加工,大小写转换,删除stopwords,增加同义词等。
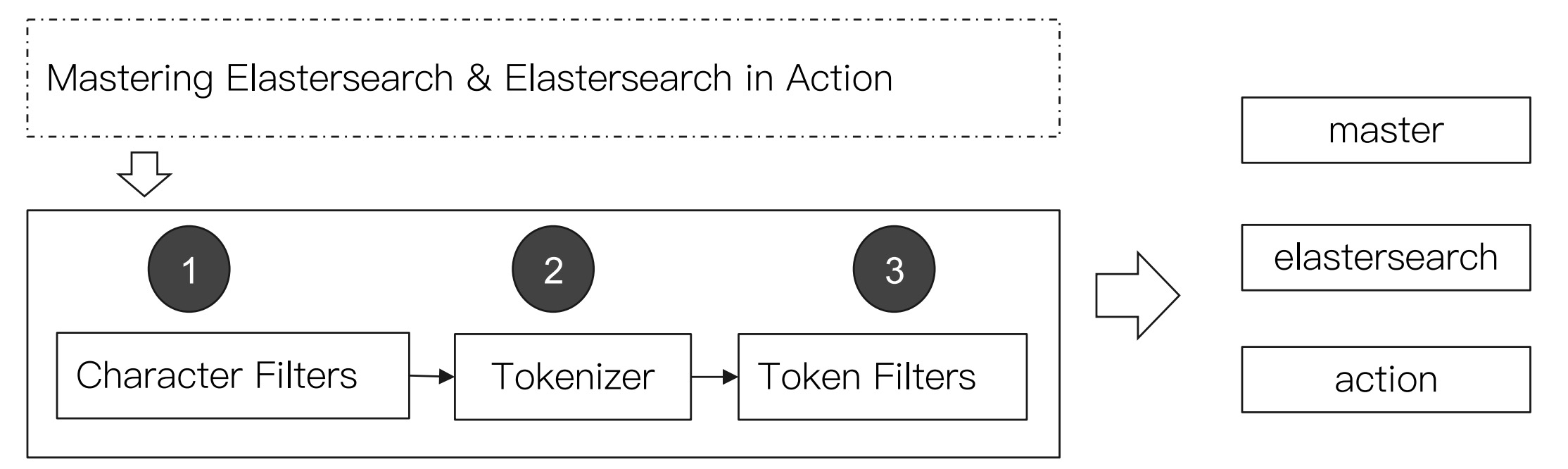
ES有很多内置的Analyser,也支持自定义Analyzer
使用_analyze API
直接指定Analyzer进行测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24POST _analyze
{
"analyzer": "standard",
"text": "Elasticsearch Essentials"
}
{
"tokens" : [
{
"token" : "elasticsearch",
"start_offset" : 0,
"end_offset" : 13,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "essentials",
"start_offset" : 14,
"end_offset" : 24,
"type" : "<ALPHANUM>",
"position" : 1
}
]
}🈯️定索引的字段进行测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18DELETE analyzer_idx
PUT analyzer_idx
{
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
POST analyzer_idx/_analyze
{
"field": "name",
"text": "中华人民共和国国歌"
}自定义分词器进行测试
1
2
3
4
5
6POST _analyze
{
"tokenizer": "standard",
"filter": ["uppercase"],
"text": "master elasticsearch"
}