
Zookeeper概述
什么是Zookeepr?
ZooKeeper 是一个分布式的,开放源码的分布式应用程序协同服务。ZooKeeper 的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
发展历史
ZooKeeper 最早起源于雅虎研究院的一个研究小组。在当时,研究人员发现,在雅虎内部很多大型系统基本都需要依赖一个类似的系统来进行分布式协同,但是这些系统往往都存在分布式单点问题。
所以,雅虎的开发人员就开发了一个通用的无单点问题的分布式协调框架, 这就是ZooKeeper。 ZooKeeper 之后在开源界被大量使用, 下面列出了 3 个著名开源项目是如何使用 ZooKeeper:
- Hadoop: 使用 ZooKeeper 做NameNode的高可用。
- HBase: 保证集群中只有一个 master, 保存 hbase:meta表的位置, 保存集群中的RegionServer 列表。
- Kafka: 集群成员管理, controller 节点选举。
应用场景
典型应用场景:
- 配置管理
- 名字服务
- 组成员管理
- 分布式锁
ZooKeeper 适用于存储和协同相关的关键数据, 不适合用于大数据量存储(需要将数据加载到内存构造成datatree,一般最多几百M)。
ZooKeeper数据模型
DataTree
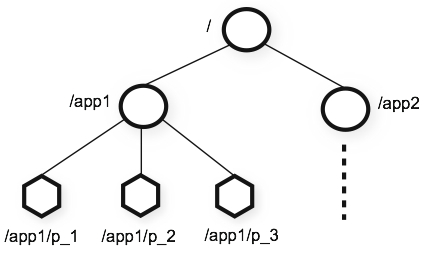
ZooKeeper 的数据模型是层次模型。 层次模型常见于文件系统。 层次模型和 key-value模型是两种主流的数据模型。 ZooKeeper 使用文件系统模型主要基于以下两点考虑:
- 文件系统的树形结构便于表达数据之间的层次关系。
- 文件系统的树形结构便于为不同的应用分配独立的命名空间(namespace)。
ZooKeeper 的层次模型称作 data tree。 Datatree的每个节点叫作 znode。 不同于文件系统, 每个节点都可以保存数据。 每个节点都有一个版本(version)。 版本从 0 开始计数
4种znode分类
一个 znode 可以是持久性的, 也可以是临时性的:
- 持久性的 znode (PERSISTENT): ZooKeeper 宕机,或者 client 宕机,这个 znode一旦创建就不会丢失。
- 临时性的 znode (EPHEMERAL): ZooKeeper 宕机了,或者 client 在指定的 timeout 时间内没有连接server ,都会被认为丢失。
- 持久顺序性的 znode(PERSISTENT_SEQUENTIAL): znode 除了具备持久性 znode 的特点之外, znode 的名字具备顺序性。
- 临时顺序性的 znode(EPHEMERAL_SEQUENTIAL): znode 除了具备临时性 znode 的特点之外, znode的名字具备顺序性。
总体架构
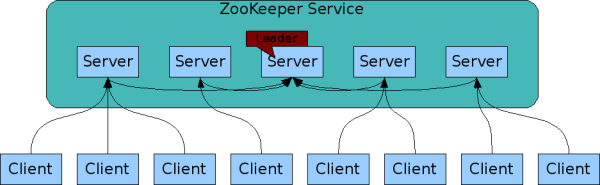
两种部署模式
- Standalone 模式: 只有一个独立运行的 ZooKeeper节点
Quorum模式: 包含多个ZooKeeper节点(一个Leader节点,多个Follower和Observer节点)。
三种角色:- Leader: 处理读写请求,与Follower和Observer保持心跳,崩溃恢复时负责恢复和同步数据
- Follower: 只处理读请求(follower 在接到写请求时会把写请求转发给leader来处理),可参与Leader选举和写操作的提议过程
- Observer: 只处理读请求,不参与Leader选举和写操作的提议过程
Session
ZooKeeper 客户端库和 ZooKeeper 集群中的节点创建一个 session(基于 TCP的长连接,默认端口为2181)。 客户端可以主动关闭 session。 另外如果ZooKeeper节点没有在 session关联的 timeout 时间内收到客户端的数据的话, ZooKeeper 节点也会关闭session。 另外ZooKeeper客户端库如果发现连接的 ZooKeeper 出错, 会自动的和其他 ZooKeeper 节点建立连接。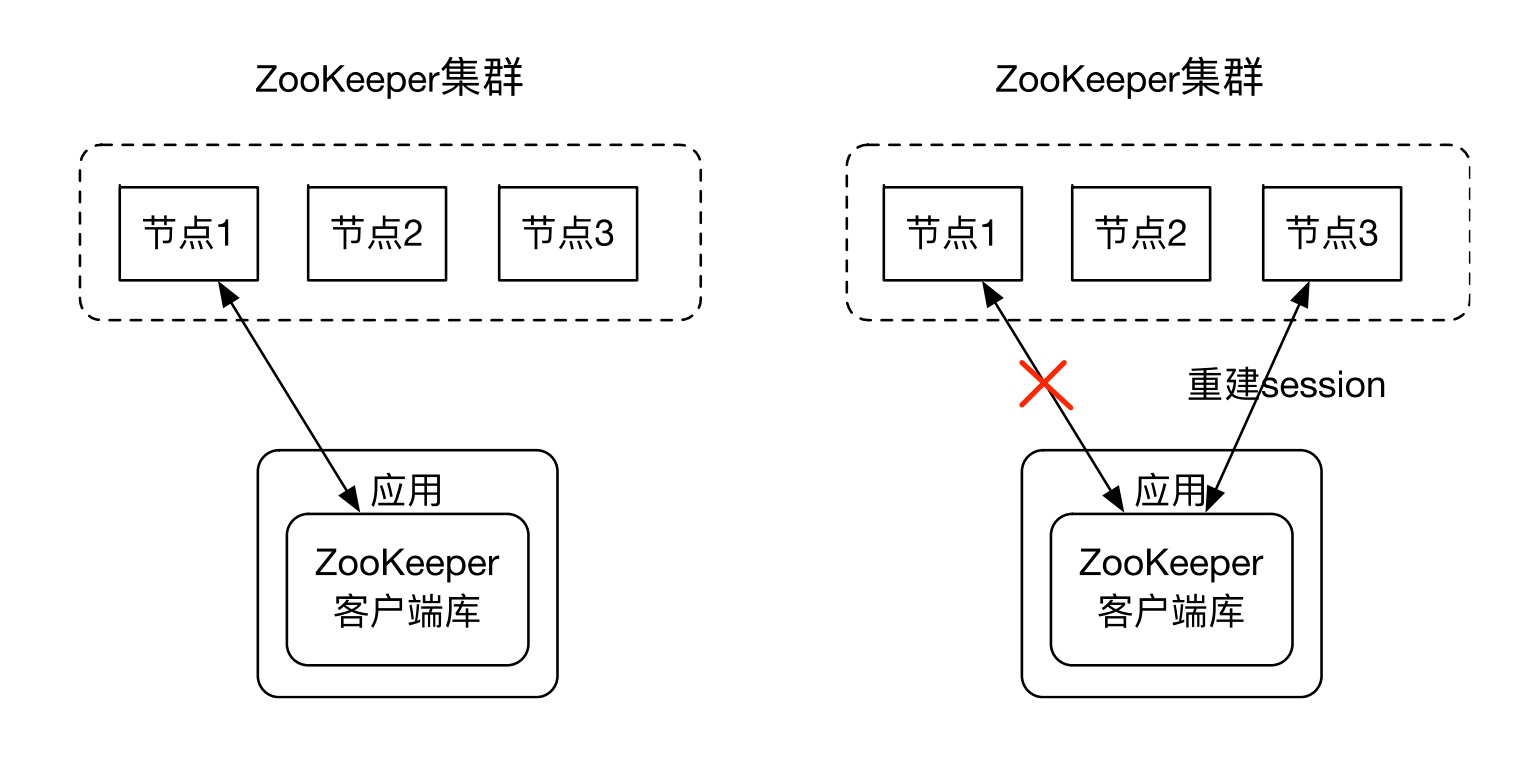
Watch机制
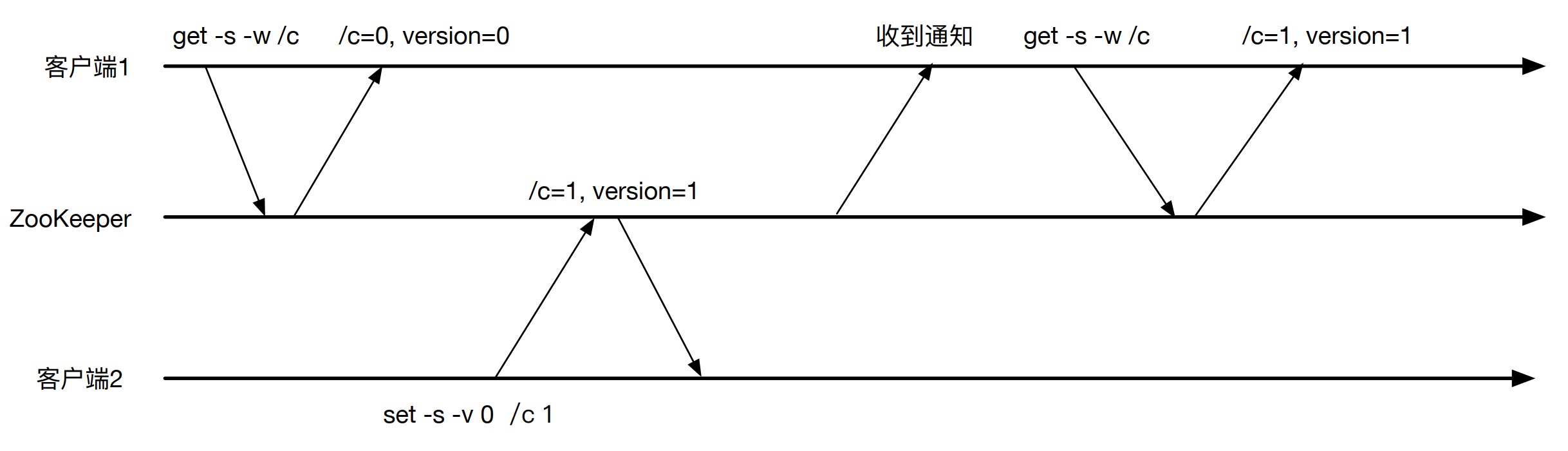
watch 提供一个让客户端获取最新数据的机制。如果没有 watch 机制,客户端需要不断的轮询ZooKeeper 来查看是否有数据更新,这在分布式环境中是非常耗时的。客户端可以在读取数据的时候设置一个 watcher,这样在数据更新时,客户端就会收到通知
常用命令
自带客户端zkCli
常用命令1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21$ ./bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 6] create -e /name longerwu
Created /name
[zk: localhost:2181(CONNECTED) 7] ls -R /
/
/name
/zookeeper
/zookeeper/config
/zookeeper/quota
[zk: localhost:2181(CONNECTED) 8] stat /name
cZxid = 0x1c
ctime = Thu May 04 13:52:19 CST 2023
mZxid = 0x1c
mtime = Thu May 04 13:52:19 CST 2023
pZxid = 0x1c
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x100156f81860000
dataLength = 8
numChildren = 0
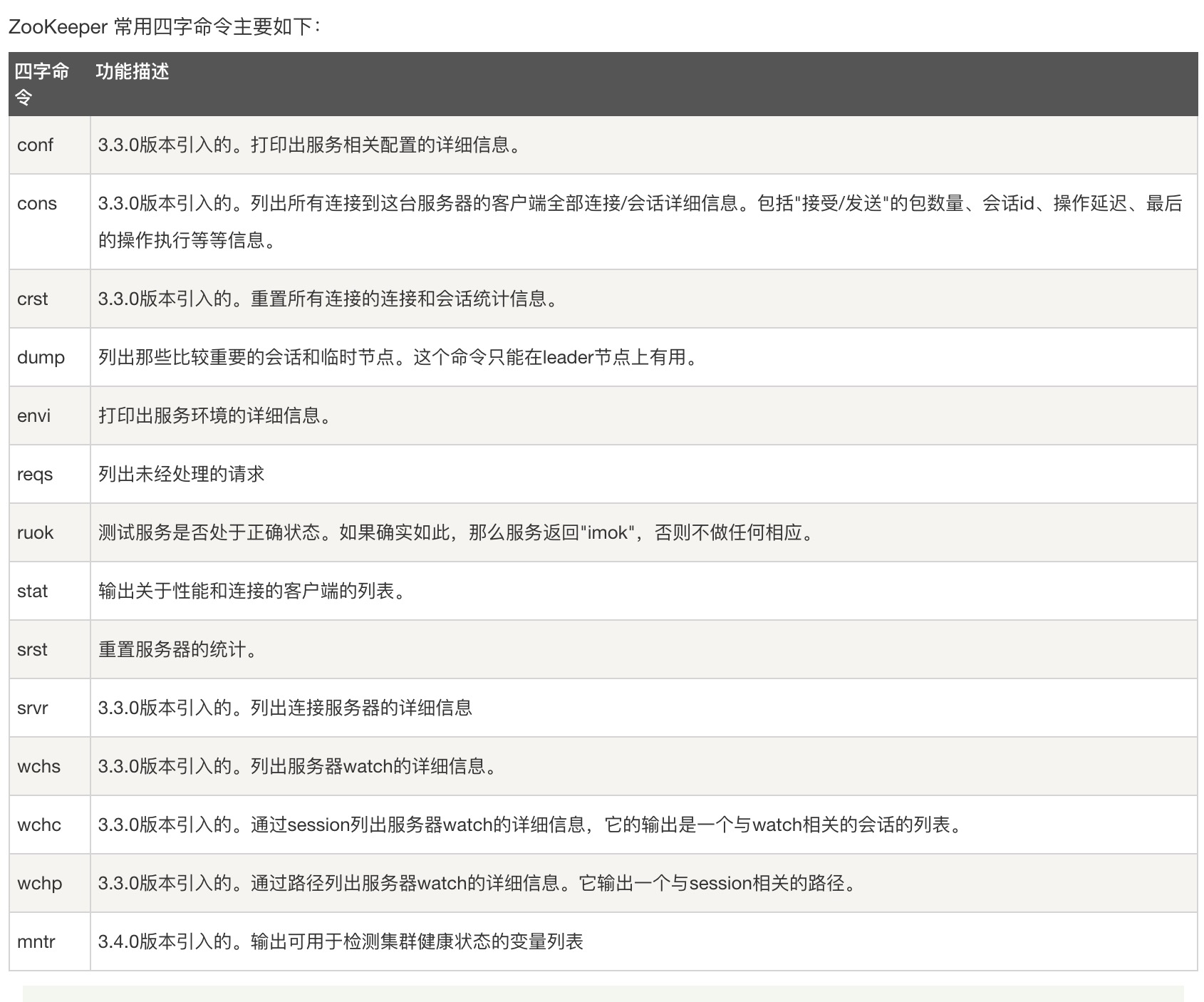
四字命令
zookeeper 支持某些特定的四字命令与其交互,用户获取 zookeeper 服务的当前状态及相关信息,用户在客户端可以通过 telenet 或者 nc(netcat) 向 zookeeper 提交相应的命令。1
2
3
4
5
6
7
8
9
10$ echo 'srvr' | nc localhost 2181
Zookeeper version: 3.7.1-a2fb57c55f8e59cdd76c34b357ad5181df1258d5, built on 2022-05-07 06:45 UTC
Latency min/avg/max: 0/0.4378/42
Received: 8505
Sent: 8504
Connections: 2
Outstanding: 0
Zxid: 0x1a
Mode: standalone
Node count: 6
Java API
Apache Curator
Apache Curator 是 Apache ZooKeeper 的 Java 客户端库。Curator 项目的目标是简化ZooKeeper 客户端的使用。例如,在以前的代码展示中,我们都要自己处理
ConnectionLossException 。另外 Curator 为常见的分布式协同服务提供了高质量的实现
分布式锁的一种实现——临时顺序节点+watch机制
基于临时顺序节点,把锁请求者按照后缀数字进行排队,后缀数字小的锁请求者先获取锁。
如果所有的锁请求者都 watch锁持有者,当代表锁请求者的 znode 被删除以后,所有的锁请求者都会通知到,但是只有一个锁请求者能拿到锁,即产生羊群效应(herd effect)。
为了避免羊群效应每个锁请求者 watch 它前面的锁请求者。每次锁被释放,只会有一个锁请求者会被通知到。这样做还让锁的分配具有公平性,锁定的分配遵循先到先得的原则。

- create EPHEMERAL_SEQUENTIAL 节点 /lock/xxx-0000000003
- 获取所有已经创建的子节点, 但不注册 watcher /lock/xxx-0000000001 /lock/xxx-0000000002 /lock/xxx-0000000003
- 如果发现自己是最小的那个, 则客户端已经获得了锁
- 如果不是最小的, 则通过调用 exists() 前一个节点 /lock/xxx-0000000002, 并注册 watcher
- 当 watcher 收到前一个节点(/lock/xxx-0000000002) node delete 事件时, 则说明自己获取了锁
缺点:
- 性能问题
因为每次在创建锁和释放锁的过程中,都要动态创建、销毁瞬时节点来实现锁功能。ZK中创建和删除节点只能通过Leader服务器来执行,然后将数据同步到所有的Follower机器上。
- 并发问题
由于网络抖动,客户端与ZK集群的session连接断了,那么zk以为客户端挂了,就会删除临时节点,这时候其他客户端就可以获取到分布式锁了。就可能产生并发问题。这个问题不常见是因为zk有重试机制,一旦zk集群检测不到客户端的心跳,就会重试
核心原理
zxid
每一个对 ZooKeeper data tree 都会作为一个事务执行。每一个事务都有一个 zxid。zxid 是一个 64 位的整数(Java long 类型)。zxid 有两个组成部分,高 4 个字节保存的是 epoch ,低 4 个字节保存的是 counter
ZAB协议&选主流程
与etcd对比
ZooKeeper 和 etcd 都是优秀的分布式协同服务平台,都有很大的生态圈。
| 功能 | Zookeeper | etcd |
|---|---|---|
| 开发语言 | Java | Go |
| 数据模型 | 层次模型 | KV模型 |
| 支持数据量 | 基于内存,几百M | 支持数据持久化,数G |
| 共识算法 | ZAB | Raft |
| 数据一致性 | 最终一致性 | 强一致性 |
| Watch特性 | 一次性触发器 | 基于 MVCC 机制,多次触发 |
| RPC | 基于Jute,仅支持Java,C等有限客户端 | 基于gRPC,支持的客户端更多 |
- ZooKeeper 更成熟,系统更稳定,文档更加完备。在大数据生态,ZooKeeper 是首选。如果研发首选语言是基于 JVM 的,建议 ZooKeeper
- etcd 的架构更先进一些。在云计算领域,etcd 是首选。如果研发首选语言是 Go,建议 etcd。
运维相关
配置项
ZooKeeper 的配置项在 zoo.cfg 配置文件中配置, 另外有些配置项可以通过 Java 系统属性来进行配置。
- clientPort : ZooKeeper 对客户端提供服务的端口。
- dataDir :来保存快照文件的目录。如果没有设置 dataLogDir ,事务日志文件也会保存到这个目录。
- dataLogDir :用来保存事务日志文件的目录。因为 ZooKeeper 在提交一个事务之前,需要保证事务日志记录的落盘,所以需要为 dataLogDir 分配一个独占的存储设备
节点硬件要求
- 内存:ZooKeeper 需要在内存中保存 data tree 。对于一般的 ZooKeeper 应用场景,8G的内存足够了
- CPU:ZooKeeper 对 CPU 的消耗不高,只要保证 ZooKeeper 能够有一个独占的 CPU 核即可,所以使用一个双核的 CPU
- 存储:因为存储设备的写延迟会直接影响事务提交的效率,建议为 dataLogDir 分配一个独占的SSD 盘。
通过Observer节点提升读性能
Observer 和 ZooKeeper 机器其他节点唯一的交互是接收来自 leader 的 inform 消息,更新自己的本地存储,不参与提交和选举的投票过程。因此可以通过往集群里面添加 Observer 节点来提高整个集群的读性能。
跨数据中心可在其中一个数据中心只部署observer节点
通过动态配置实现不中断服务的集群成员变更
3.5.0 新特性 - dynamic reconfiguration,可以在不停止 ZooKeeper 服务的前提下,调整集群成员
参考资料:
- 《从Paxos到Zookeeper》
- 官方文档
- 极客时间-ZooKeeper 实战与源码剖析
- 极客时间——分布式协议与算法实战
- 七张图彻底讲清楚ZooKeeper分布式锁的实现原理